Redrawing the map of cancer genome research
Cancer’s genetic causes are more diverse than previous scientific studies have indicated – a conclusion reached by researchers from ETH Zurich and University Hospital Zurich. Through their participation in an international research collaboration, they helped compile the most comprehensive catalogue to date of gene alterations associated with cancer. Their work was based on the analysis of whole cancer genomes.

Never before has there been such a large-scale study of the genetic causes of cancer: over 1,300 researchers from 37 countries and more than 70 research institutes joined forces in the Pan-Cancer Analysis of Whole Genomes Project (PCAWG), or Pan-Cancer Project for short, to explore exactly how the human genome triggers the development of cancer.
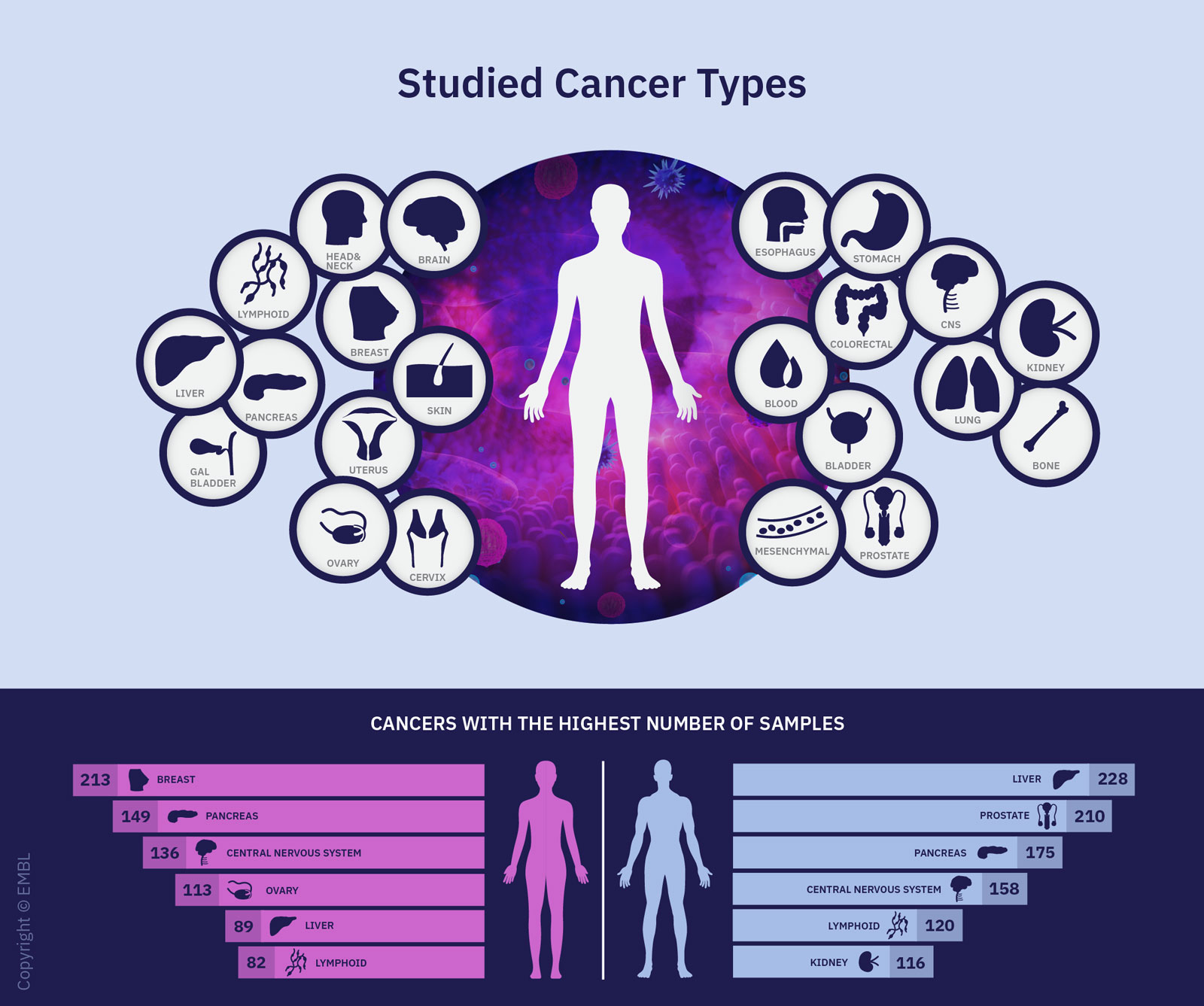
The project focused on alterations in the genome that are implicated in cancer. Genomes are biological storage media that contain the entirety of a cell’s genetic information. In the Pan-Cancer Project, the researchers analysed more than 2,600 whole genomes of 38 types of tumours, mapping nearly every cancer genome that was accessible at the time the project was launched.
The data set analysed covered the genomic data of 2,658 donors from 48 cancer research projects. No Swiss patient data was used in the study. Such a vast amount of data, as well as the technical advances necessary for exchanging and analysing that data, was key to gaining an understanding of the genomic changes.
A more complete picture of the cancer genome
The results of this international research collaboration were published today in 23 scientific articles in the prestigious magazine Nature and its affiliated journals. According to a external page press release from the PCAWG consortium, researchers are close to cataloguing all of the biological pathways involved in cancer and having a fuller picture of their actions in the genome. One primary finding is that, while the cancer genome is finite and knowable, it is also enormously complicated.
Tumour types can be identified accurately according to the patterns of genetic alterations seen throughout the genome. Whereas previous studies focused on just roughly 1 percent of the genome, the Pan-Cancer Project explored the remaining 99 percent in considerably greater detail, including key regions that control switching genes on and off and so can trigger mutations that cause cancer. The entire endeavour can thus be described as redrawing the map of cancer genome research.
“In principle, we have put the various pieces of the puzzle together to form a more complete picture. Now we can read almost the whole cancer genome, even if there is still quite a way to go before we understand all the individual parts,” says Gunnar Rätsch, Professor of Biomedical Informatics at ETH Zurich and University Hospital Zurich.
As part of the Pan-Cancer Project, he led a working group alongside Professor Angela Brooks from the University of California, Santa Cruz, and Professor Alvis Brazma from the European Bioinformatics Institute (EMBL-EBI). Their group looked into how alterations in RNA genetic information can impact the emergence of cancer. In a paper published in Nature, they have now presented the most comprehensive catalogue of cancer-specific RNA alterations to date.

Causes of cancer at the RNA level
The Pan-Cancer Project focused on DNA changes that cause cancer, investigating genomic changes that are inherited as well as those that occur in a person’s lifetime. In the cell, the information stored in the DNA is transcribed into RNA, which is then translated into further gene products. Changes in the RNA can also explain how cancer develops, as the group of authors co-led by Rätsch have now shown based on a very extensive pool of data.
“No one has ever performed such a comprehensive analysis to demonstrate the major role that RNA alterations play in the development of cancer. This is new,” Rätsch says. In some genes, such as the one that plays a key role in insulin metabolism and diabetes (IGF2), changes occur very frequently in the RNA, but none in the DNA. Moreover, it is likely that DNA and RNA changes together cause cancer. Research into this interaction has been so far been relatively limited.
To better understand the process, it’s helpful to think about it like this: DNA is the inherited part of genetic information and thus serves as the “template” for forming RNA, which in turn produces vital proteins. Errors that occur during RNA formation may lead to cancer. In their study, the researchers examined genome data from 1,188 donors, containing both RNA and DNA sequencing samples.
731 cancer-relevant genes
To create their catalogue of cancer-driving mutations, the researchers drew on data from 27 distinct tumour types and 731 genes that could cause cancer if altered. These include genes that change predominantly at the DNA level (such as TP53) and genes whose alteration occurs most frequently in the RNA (such as GAS7 or IGF2). A total of 87 tumour samples showed changes only to the RNA and not the DNA.
The researchers discovered 649 cases in which cancer-related errors occurred in copying and translating DNA into RNA, 1,901 changes caused by RNA splicing, and a new class of gene fusion (75 cases). In RNA splicing, entire sequences are removed, or spliced out, from the RNA and reassembled. This can result in previously inactive genes being “switched on” in a way that is conducive to cancer development. A similar situation may arise if genes fuse together.
In total, the researchers identified seven categories of RNA alterations related to cancer. “If you look at RNA alterations in relation to hereditary and non-hereditary changes within the genome, you can identify other genes and genetic mechanisms involved in cancer,” says André Kahles, who, alongside Natalie Davidson and Kjong Lehmann, is part of Rätsch’s research group at ETH Zurich. Together, they all played a leading role in the study. Their catalogue of RNA alterations is a valuable new resource for research into the causes, prevention, diagnosis and treatment of cancer.
Leonard Med system made it possible
A key factor in the project’s success was the IT infrastructure at ETH. When Rätsch and his team came to ETH Zurich four years ago from Memorial Sloan Kettering Cancer Center in New York, they joined forces with ETH’s IT Services to set up the Leonhard Med computer system. The memory and computer cluster is specially designed to recognise and compute patterns in huge amounts of medical data. In terms of its available memory, the system operates extremely fast and meets all the special data protection and security requirements that apply to medical data.
“If it weren’t for Leonhard Med, we wouldn’t have been able to participate in this research collaboration,” Rätsch says. He is also a member of the Swiss Institute of Bioinformatics, which coordinates the field of bioinformatics and the corresponding database in Switzerland.
The Pan-Cancer Project
The Pan-Cancer Analysis of Whole Genomes (PCAWG) project, known as the Pan-Cancer Project, is an international research collaboration coordinated by five leading institutions from the external page International Cancer Genome Consortium: the European Molecular Biology Laboratory, the Ontario Institute for Cancer Research, the Broad Institute of MIT and Harvard, the Wellcome Sanger Institute and the University of California, Santa Cruz.
It aims to understand the genomic changes in many forms of cancer worldwide, with a view to enabling further research into the causes, prevention, diagnosis and treatment of cancers. It builds on previous large-scale projects such as external page The Cancer Genome Atlas and external page Chromothripsis Explorer.
external page PCAWG Portal — Pan-Cancer Analysis of Whole Genomes.
Reference
PCAWG Transcriptome Core Group, et al. Genomic basis for RNA alterations in cancer. Nature 2020, doi: external page 10.1038/s41586-020-1970-0 .
The European Molecular Biology Laboratory (EMBL) and Nature have a collection of all PCAWG papers and related content, available at:
Comments
No comments yet